Schema On The Fly: Three ScopeDB Design Principles (Part 2)
What Is a Data Schema?
A data schema defines how data is organized and structured within a data system.
It acts as a structural guide that specifies the types of data, i.e., what specific attributes or pieces of information the data consists of.
Take an application observability platform for example. A sample event would looks like:
{
"time": "2025-09-30T12:34:56Z",
"container_id": "yx_9ch8p",
"message": "Application started",
"message_length": 20,
"name": "my-app",
"env": "production",
"version": "1.0.0",
"srcloc": {
"file": "/app/main.go",
"line": 42
}
}Your data schema might define that an event always contains an observed timestamp (timestamp), a container name (string), a message (string), its length (integer), and an application name (string). Besides, other attributes are variable or even nested.
This structure ensures that everyone, from data engineers to business analysts, knows exactly what to expect and what to look for when working with event data. Without a data schema, you can hardly predict the structure and content of incoming events.
A data schema is the foundation for keeping your data consistent and reliable.
When Data Schema Becomes a Problem?
Typical relational databases (RDBMS) enforce a rigid schema. Before you can store any data, you must define the schema upfront using DDL (Data Definition Language) statements like CREATE TABLE and ALTER TABLE.
A prior schema definition ensures data integrity and consistency. However, in many real-world scenarios, data often evolves quickly and unpredictably with new fields and dimensions. For example, application developers may frequently add new attributes to their structured logs and events to capture more context. This results in the impossibility of defining a fixed schema in advance.
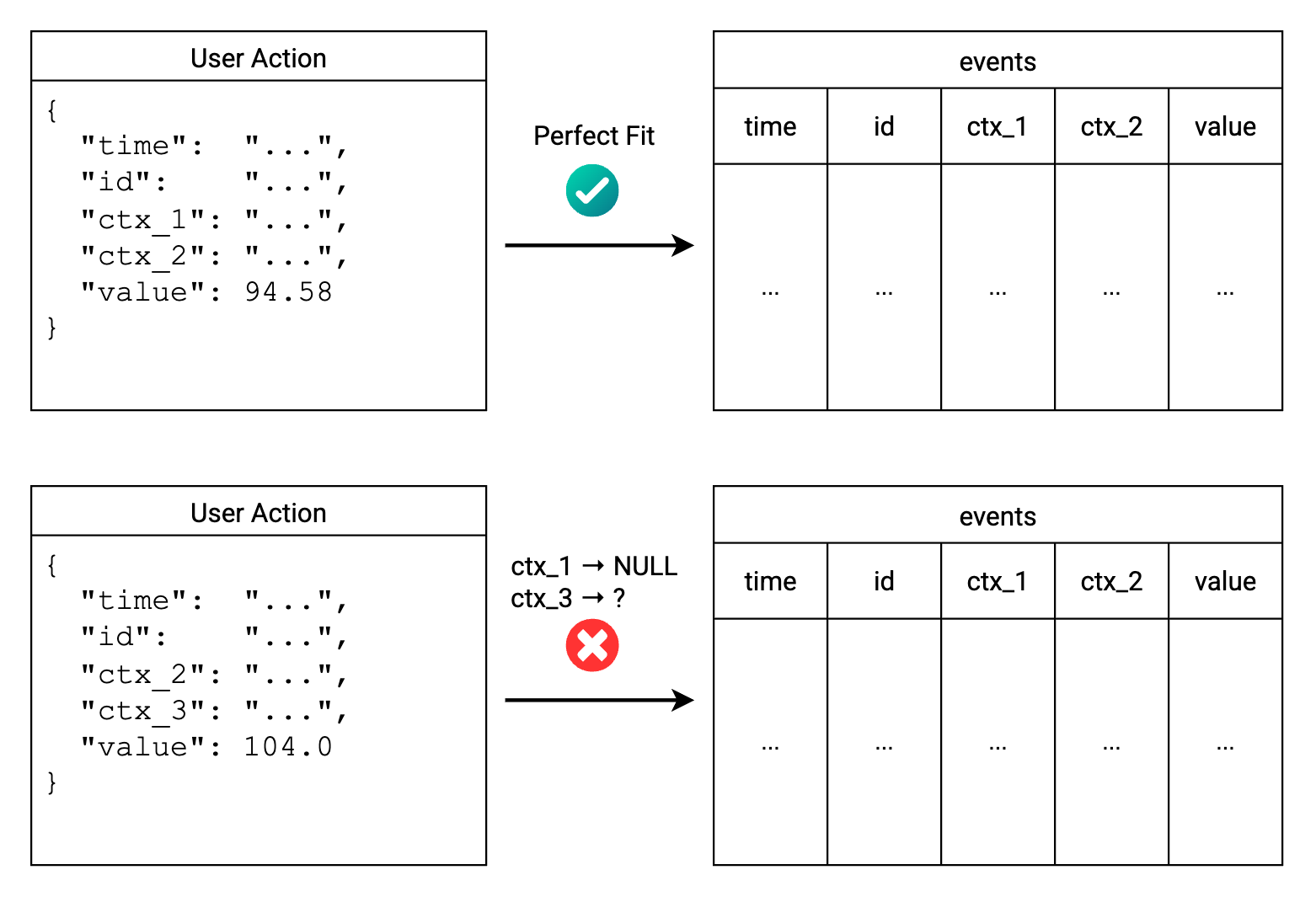
To accommodate evolving data, NoSQL databases such as MongoDB and Elasticsearch adopt a schemaless approach. They allow you to store data without a predefined schema, providing flexibility to handle dynamic and unstructured data.
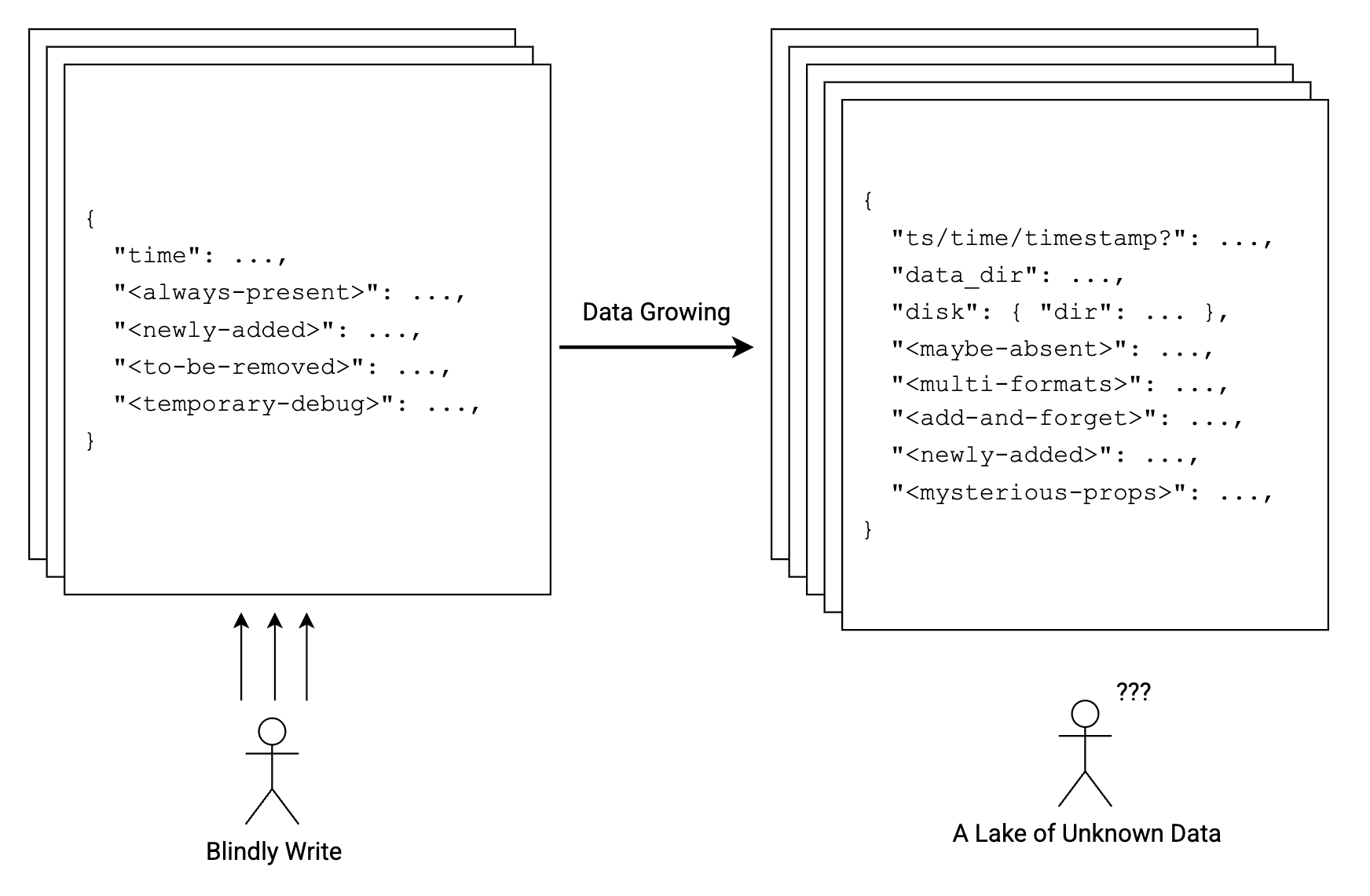
No schema enables rapid development and iteration. However, when your business sustains and your data continues to grow, the lack of a schema results in knowledge loss for your data. Over time, this can lead to a fragmented understanding of your data landscape, making it challenging to derive insights from a lake of unknown data.
Schema On The Fly: An Ideal Data Schema Solution
To balance the trade-offs between a fixed schema and a schemaless approach, ScopeDB introduces the design principle: "Schema On The Fly."
Generally, ScopeDB models data as a collection of tables, where each table is still associated with a schema. The difference is that, unlike traditional relational databases, table columns can be of a variant data type, which can hold arbitrary data structures such as nested objects and arrays.
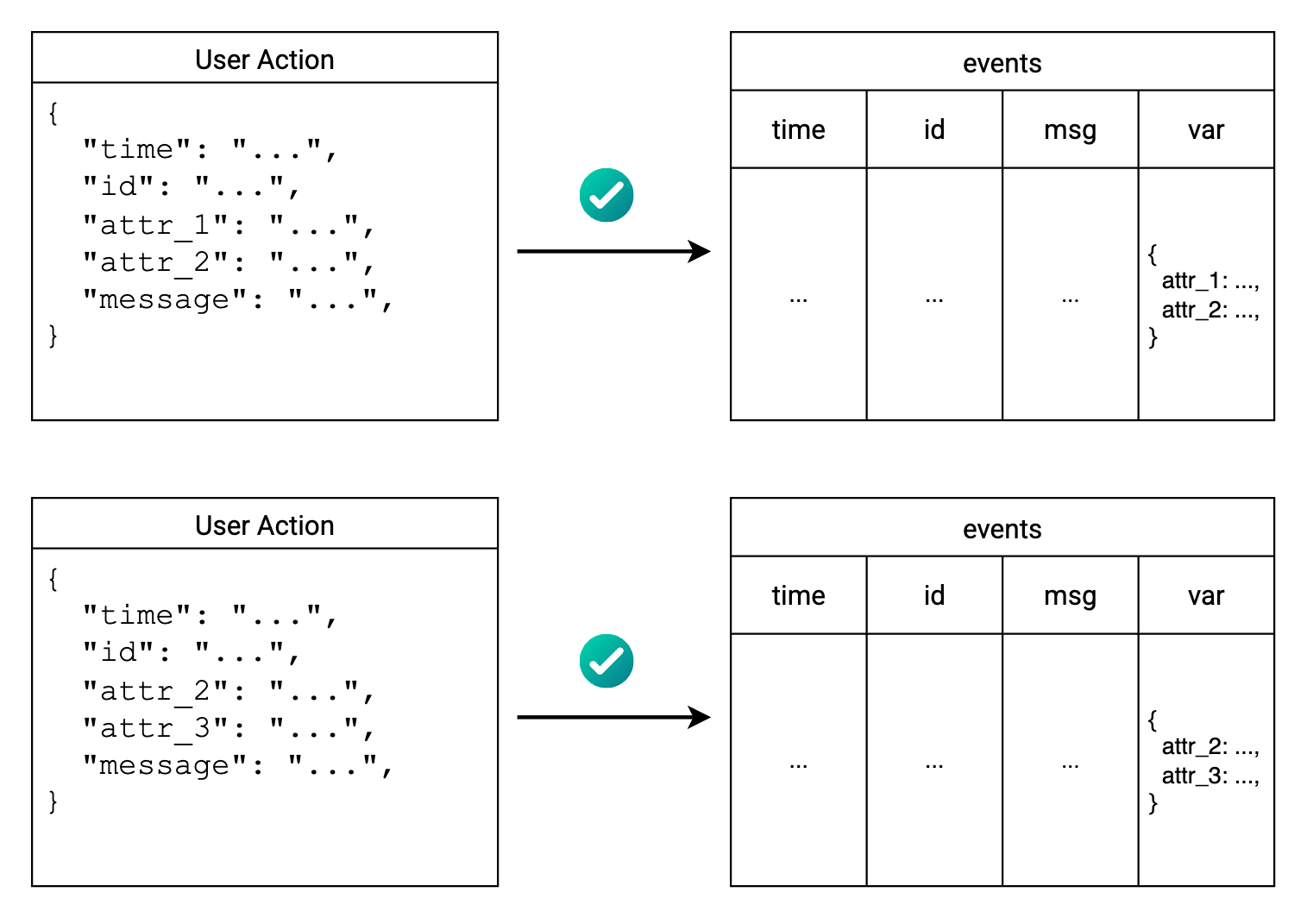
As you can see, unpredictable attributes go into the object column, while fixed fields are stored in dedicated columns. This hybrid schema design provides the flexibility to handle raw events with dynamic structure, while still maintaining an overall structured format for all events.
Take the above event as an example. You can define a table schema as follows:
CREATE TABLE events (
time timestamp,
container_id string,
message string,
message_length int,
name string,
var object
);Despite the object type looking similar to a JSON type, they are fundamentally different. ScopeDB has an any type that can hold any data. All concrete types are an enum variant of any. An object is a map of string to any, and an array is a list of any. This means ScopeDB implements a real variant type system, where each value is stored in a compact binary format.
Besides the semi-structured data model, ScopeDB implements a full-featured flexible schema solution that allows users to:
- Ingest raw events with transformation rules to reshape the events into fixed fields and variant fields.
- Query and index nested fields within the object column efficiently.
- Evolve the schema of existing tables online without downtime or data migration.
Let's explore how these features work.
Schema On Write: Reshaping Raw Events
In contrast to NoSQL databases that write raw events as-is blindly, when ingesting data into ScopeDB, users define a set of rules to transform raw events into a semi-structured format.
Take the very first event and table events as an example. A transform rule can be defined in ScopeQL as:
SELECT
$0["time"]::timestamp AS time,
$0["container_id"]::string AS container_id,
$0["message"]::string AS message,
$0["message_length"]::int AS message_length,
$0["name"]::string AS name,
$0::object AS var
WHERE time < NOW() + 'PT1h'::interval
AND time > NOW() - 'PT1h'::interval
AND name IS NOT NULL
INSERT INTO eventsThis rule extracts fixed fields from the raw event and casts them to the appropriate types. Meanwhile, the raw event is stored into the var object column.
As it is written in ScopeQL, this transformation rule can be shared and reused across multiple data sources, regardless of their language or framework. ScopeDB SDKs are to offer seamless integrations with popular programming languages and frameworks, enabling users to send raw events directly to ScopeDB with minimal code modifications.
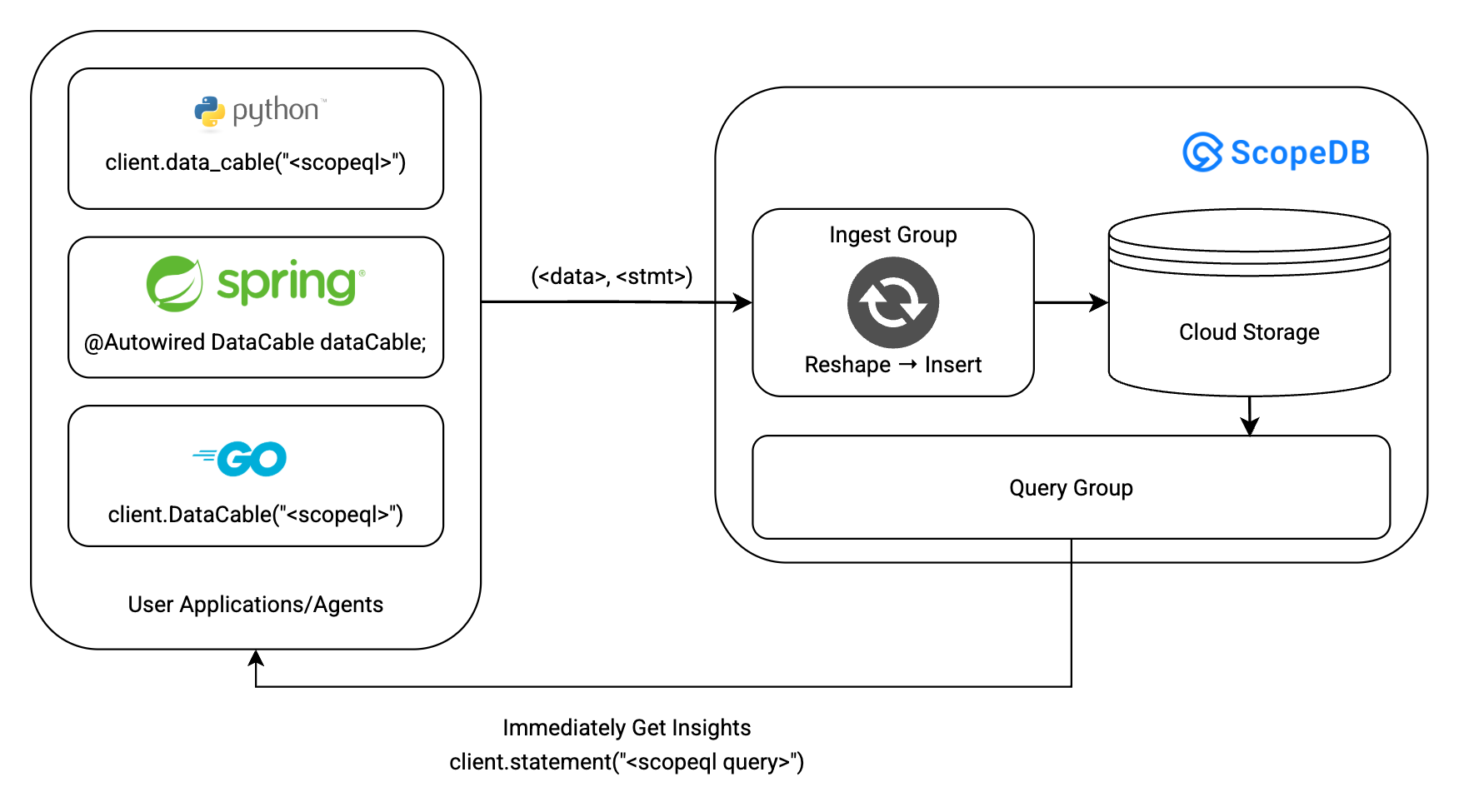
User applications can send raw events to ScopeDB via a data cable, which applies the transformation rules and writes the transformed events into the target table. The applications can also immediately get insights from the data ingested by the data cable. This data flow eliminates the need for any further ETL processes, thereby significantly reducing the time and effort required to prepare data for analysis.
Since the transformation rules are defined within the application codebase, they can be versioned and evolved alongside the application itself. This ensures that as the application changes, the data ingestion process remains aligned with its current state, maintaining data integrity and relevance.
Supposed a Go app defines event structure and data cable as follows.
type SourceLocation struct {
File string `json:"file"`
Line int `json:"line"`
}
type Event struct {
Time time.Time `json:"time"`
ContainerID string `json:"container_id"`
Message string `json:"message"`
MessageLength int `json:"message_length"`
Name string `json:"name"`
Env string `json:"env"`
Version string `json:"version"`
SourceLocation SourceLocation `json:"srcloc"`
}
cable := client.DataCable(`
SELECT
$0["time"]::timestamp AS time,
$0["container_id"]::string AS container_id,
$0["message"]::string AS message,
$0["message_length"]::int AS message_length,
$0["name"]::string AS name,
$0::object AS var
WHERE time < NOW() + 'PT1h'::interval
AND time > NOW() - 'PT1h'::interval
AND name IS NOT NULL
INSERT INTO events
`)Now, assuming the application now records the HTTP URL for each request event, and would like to filter out events with dedicated URL patterns. The application developer can simply update the Event struct and the transformation rule as follows:
type Event struct {
...
HttpUrl string `json:"http_url"`
}
cable := client.DataCable(`
SELECT
$0["time"]::timestamp AS time,
$0["container_id"]::string AS container_id,
$0["message"]::string AS message,
$0["message_length"]::int AS message_length,
$0["name"]::string AS name,
$0["http_url"]::string AS http_url,
$0::object AS var
WHERE time < NOW() + 'PT1h'::interval
AND time > NOW() - 'PT1h'::interval
AND name IS NOT NULL
AND NOT regexp_like(http_url, "/path/to/data.*")
AND NOT search(http_url, "/path/to/directory")
SELECT * EXCLUDE http_url
INSERT INTO events
`)By versioning the business logic and transformation rules together, the application developer can ensure that the data ingestion process remains consistent with the application's evolving requirements. This approach minimizes the risk of data discrepancies and enhances the overall reliability of the data pipeline.
Schema On Read: Exploring Variant Data
Now that you store all flexible attributes in a var object column, how can you query (nested) fields within it?
The syntax is straightforward. You can use the bracket notation to access nested fields. For example, to get the file field within the srcloc object, you can write:
FROM events SELECT var["srcloc"]["file"]::string AS file;Consider an application observability platform powered by ScopeDB, for example. When exploring the event data (logs, traces, etc.), users may want to understand the distribution of events across different hosts and containers. They can easily extract these fields from the var object column and perform aggregations:
FROM events
SELECT *, var["machine"]["host"]::string AS host,
WHERE time > NOW() - 'PT24h'::interval
AND host IS NOT NULL
AND container_id IS NOT NULL
GROUP BY host, container_id
AGGREGATE COUNT() AS event_count
ORDER BY event_count DESC
LIMIT 10;ScopeDB provides typeof and keys functions to help users explore the structure of the variant data. Thus, all the flexible attributes would be available for ad-hoc queries and explorations without any prior knowledge of the data schema.
Schema On Maintenance: Online Schema Evolution
As your data evolves, you may notice some attributes are frequently used in queries. To improve query performance and provide clear semantics, you can create indexes on these access paths within the object column:
CREATE EQUALITY INDEX ON events ((var["machine"]["host"]::string));
CREATE RANGE INDEX ON events ((var["session"]["dwell_time"]::interval));
CREATE SEARCH INDEX ON events ((var["http_url"]::string));
CREATE MATERIALIZED INDEX ON events ((var["user"]["id"]::string));Indexes are created online without any downtime. The existing data will be backfilled in the background, while new incoming data will be indexed immediately.
Each index can speed up queries that filter the corresponding access path, and a materialized index can even speed up more calculations. You can regard a materialized index as a computed column, which eliminates the need to scan the entire variant column for each query. When the indexed access path is frequently used in queries, a materialized index can significantly improve query performance.
When the access path become stable, you may want to factor them out from the object column into dedicated columns (e.g., var["machine"]["host"]::string → host). ScopeDB supports adding columns in this scenario:
ALTER TABLE events ADD COLUMN host string;This action is instantaneous and does not require any data migration. The new column host is simply added to the table schema, and all existing records will have a NULL value for this column. You can now access the host field directly, or if you still want to access old records, you can write a condition to extract it from the object column:
FROM events SELECT IF(host IS NOT NULL, host, try(var["machine"]["host"]::string)) AS host;After the new column is added, you can update the transformation rule to populate the host column directly when ingesting new events:
SELECT
...
$0["machine"]["host"]::string as host,
$0::object AS var
WHERE time < NOW() + 'PT1h'::interval
AND time > NOW() - 'PT1h'::interval
AND name IS NOT NULL
INSERT INTO events (..., host)Note that before updating the transformation rule, the previous rule will still function, with the host column populated as NULL. This online schema evolution process allows you to gradually refine your data schema over time without any downtime or data migration.
Conclusion
In this blog post, we first examine how rigid schemas and schemaless approaches can be problematic in real-world scenarios. To address these challenges, ScopeDB introduces the "Schema On The Fly" design principle, which combines the benefits of both approaches.
ScopeDB implements a real variant type system that supports both structured and semi-structured data. It provides a full-featured, flexible schema solution that allows users to reshape raw events into a semi-structured format during ingestion, query and index nested fields within the object column efficiently, and evolve the schema of existing tables online without downtime or data migration.
If you're interested in evaluating ScopeDB, or just want to get your hands dirty, drop us an email for onboarding guidance, as well as to access the free trial endpoint.