Insight In No Time: Three ScopeDB Design Principles (Part 1)
TL;DR
ScopeDB allows users to get insights in no time by eliminating the ETL process and enabling direct data analysis and exploration for multiple scenarios. This is achieved through three key features:
- Users can directly ingest data into ScopeDB in real-time with producer style APIs.
- Users can apply transformations on the fly during ingestion, with the unified query language ScopeQL.
- Users can run various analytical queries efficiently, including both real-time serving and batch processing.
What Slows Down Your Data Pipeline
Let's start with a picture of how current data engineering work:
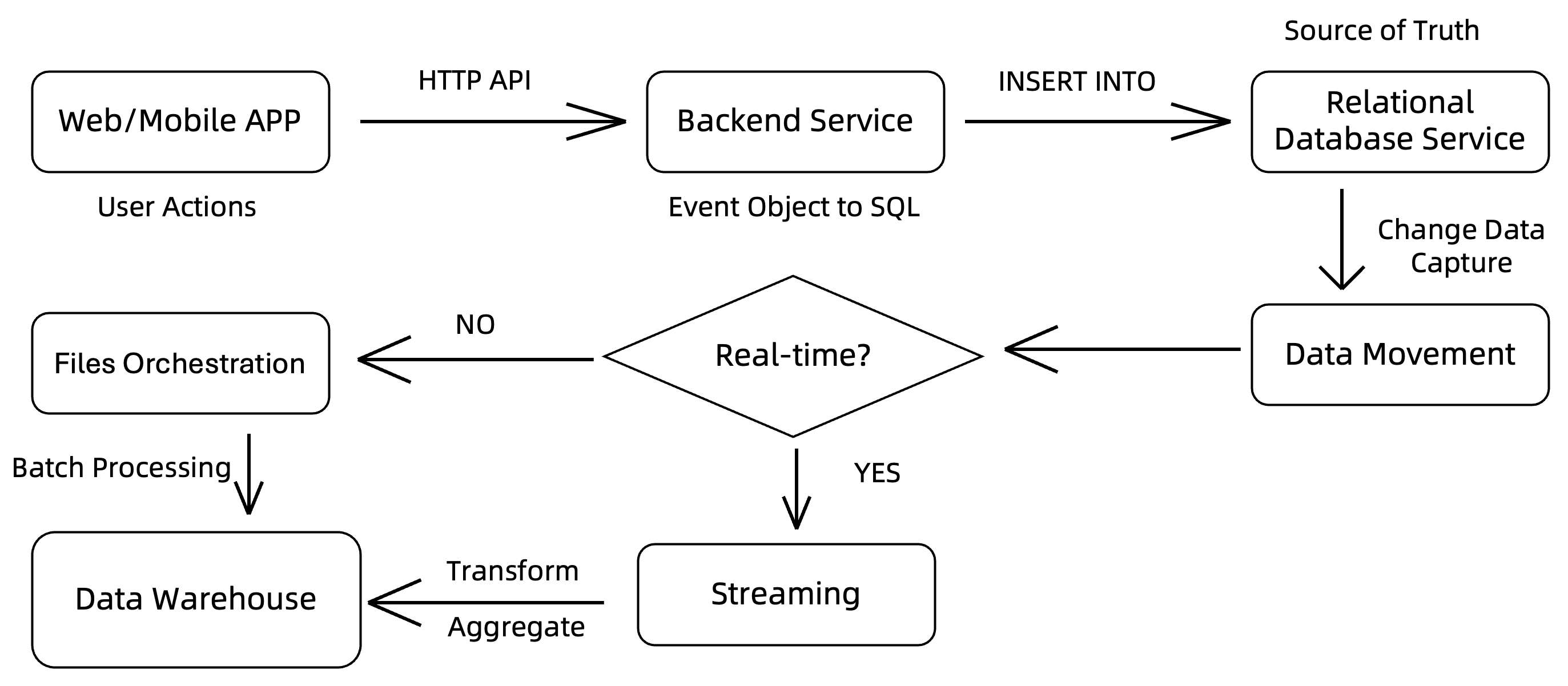
First, events, like user actions, are sent to the backend service via HTTP API calls. When the backend service receives these events, it processes them, turns event objects into rows with a rigid schema, and stores them into a relational database.
If the data set is small enough, developers can run analytical queries directly against the database to gain insights. However, as the data volume grows, this approach becomes increasingly difficult and inefficient. To address this, the current data engineering practices gradually introduce new components to cover different analysis needs.
A data movement platform is added to dispatch data ingestion from different sources to various processing systems. A streaming framework can be one of those processing systems to apply data cleaning, transformation, or aggregation in real-time, and then bulk load the processed data into a data warehouse or a data lake. A batch processing framework can also be introduced to handle large-scale data processing tasks that are not time-sensitive.
Each additional step in this extract, transform, and load (ETL) process introduces more complexity and potential bottlenecks, making it harder to deliver timely insights. The complexity encompasses the need for data quality checks, data schema reconciliation, and orchestration of operations across various systems.
Get Data Insights From the Beginning
One of ScopeDB's design principles is to provide insights in no time. We achieve this by eliminating the ETL process and enabling direct data analysis and exploration for multiple scenarios. Below are the key features that make it possible:
- Users can directly ingest data into ScopeDB in real-time with producer style APIs.
- Users can apply transformations on the fly during ingestion, with the unified query language ScopeQL.
- Users can run various analytical queries efficiently, including both real-time serving and batch processing.
ScopeDB greatly simplifies your data pipeline as follows:
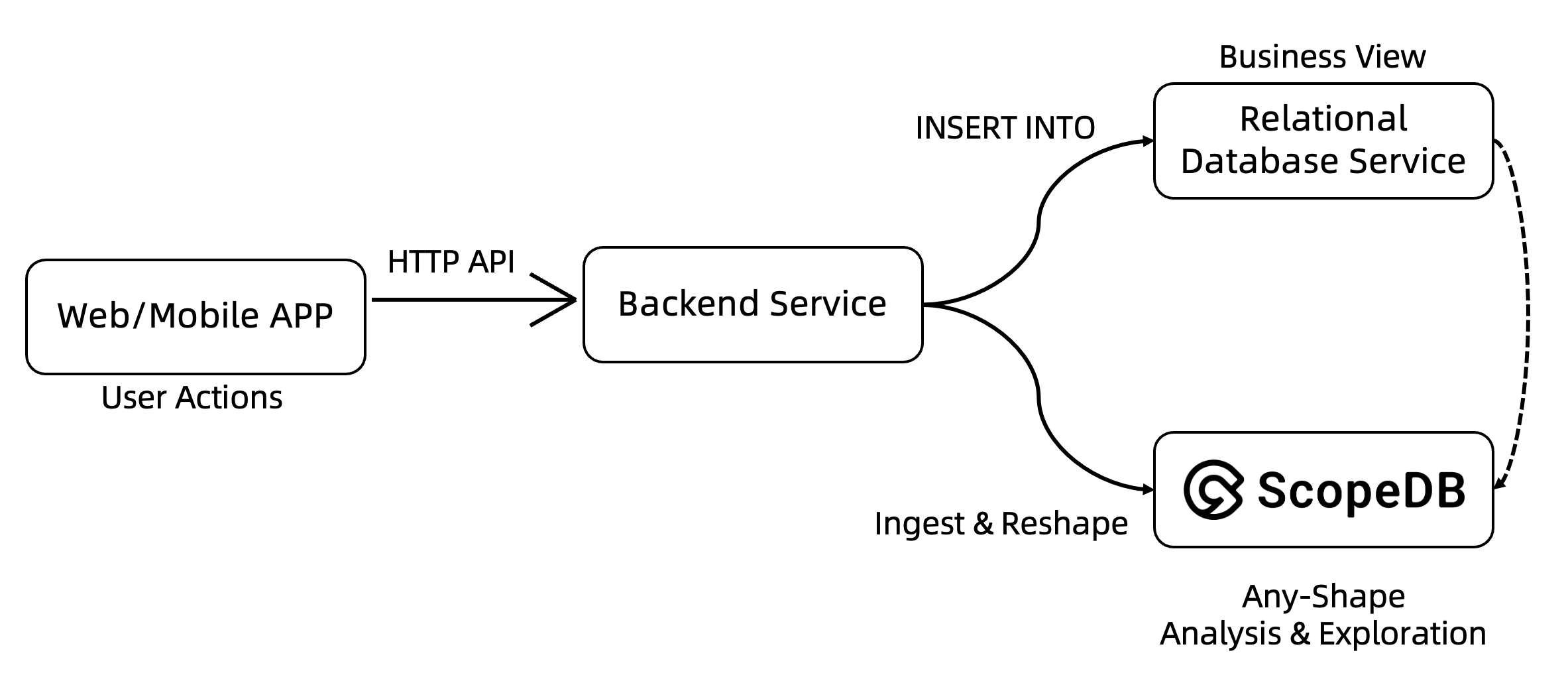
You may notice that the data flow of insights is now equal to transactions, rather than being a downstream consumer. Although it is still possible to capture data changes of transactions as supplementary events, the ScopeDB-powered architecture encourages users to get insights from user actions from the beginning.
Real-time Ingestion With Transformation
Traditional data warehouses typically require a separate ETL pipeline to load data in large, pre-processed batches. This architecture introduces a data movement platform like Apache Kafka, probably combined with Debezium or Apache Flink, to capture and stream changes in real-time.
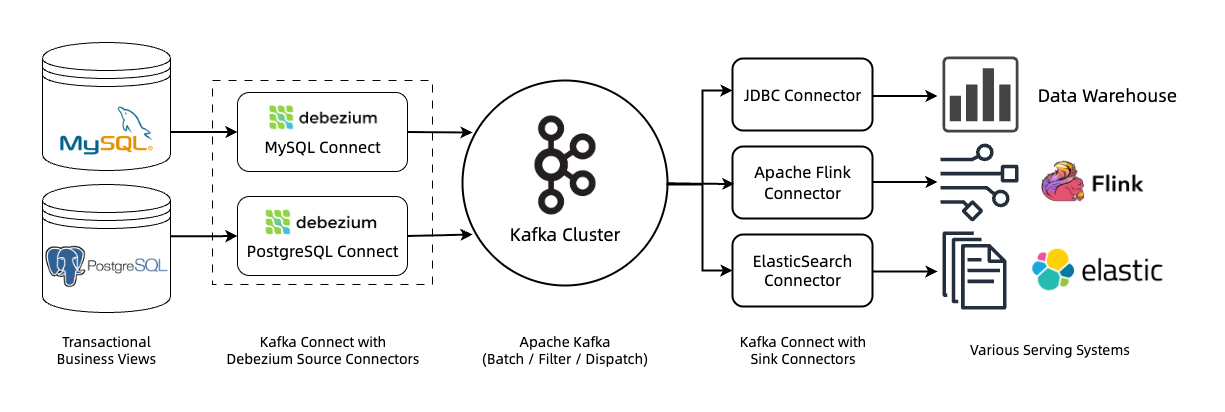
As shown above, building such an ETL pipeline involves numerous intermediate components, each consisting of its own storage, compute, and coordination logic. In consequence, (1) the end-to-end latency can be high even if each component is "in real-time"; (2) the operational complexity is significant; (3) the data schema among different systems must be reconciled, which is often error-prone and hits the impedance mismatch issue.
ScopeDB implements direct ingestion APIs similar to producer APIs in messaging systems. Users can construct a data cable and then send data as language-native objects directly to ScopeDB, eliminating the need for any additional intermediate systems. Once the send future gets resolved, the data is durably stored in ScopeDB and will be available for querying. Take Go SDK's example:
client := scopedb.NewClient(...)
cable := client.DataCable(...)
cable.Start(ctx)
defer cable.Close()
type CustomData struct {
Timestamp int64 `json:"time"`
Name string `json:"name,omitempty"`
Var map[string]any `json:"var"`
}
// waiting for the event being recorded durably
err := <-cable.Send(CustomData{
Timestamp: 335503360000000,
Name: "scopedb",
Var: map[string]any{"date": 1759052663727198000},
})
if err != nil { ... }
// do not await the result to fire and forget
cable.Send(CustomData{
Timestamp: 335503360000000,
Name: "percas",
Var: map[string]any{"desc": "cache service"},
})The sent data is interpreted as one single object column that has multiple fields. For example, the above two records will be interpreted as follows:
{ "time": 335503360000000, "name": "scopedb", "var": { "date": 1759052663727198000 } }
{ "time": 335503360000000, "name": "percas", "var": { "desc": "cache service" } }To turn the data into target table's columns, the data cable allows users to specify arbitrary ScopeQL transformations during ingestion. For example, the following transformation extracts the timestamp, name, and var fields from the object column and applies filtering conditions to ensure data quality:
WHERE time > NOW() - <retention interval>
AND time < NOW() + <maximum future time drift>
AND time > NOW() - <maximum past time drift>
AND name IS NOT NULL
SELECT * REPLACE PARSE_JSON(var) as var
INSERT INTO my_table (time, name, var)This transformation is defined when constructing the data cable:
cable := client.DataCable(`
SELECT
$0["time"]::timestamp,
$0["name"]::string,
$0["var"]::any,
WHERE time > NOW() - 'PT24h'::interval
AND time < NOW() + 'PT1h'::interval
AND time > NOW() - 'PT1h'::interval
AND name IS NOT NULL
INSERT INTO my_table (time, name, var)
`)ScopeQL is the universal query language of ScopeDB. Developers write ScopeQL for both ingestion reshaping and any-shape queries. Since there is a single data type system and a single data query language, users do not need to learn different data modeling methods or reconcile disparate data schemas across various systems.
To sum up, users can directly insert data into ScopeDB in both small and large batches. Data cable supports on-the-fly transformations during ingestion, enabling users to apply data cleaning and normalization without requiring a separate ETL process.
P.S. Some data warehouses do not support real-time ingestion because they employ a shared-nothing architecture where the leader replica should handle both read and write workload; thus, the writes can interfere with reads, and vice versa. ScopeDB delegates both data replication and fault tolerance to shared-disk object storage, thereby achieving a pure read/write splitting architecture, where writes consume isolated resources and never impact reads. We'll explore this further in the following blog about adopting full cloud elasticity.
Any-Shape Analysis & Exploration
Current data engineering practices involve multiple data systems to handle various types of analytical queries. Real-time serving systems are optimized for low-latency queries, while batch processing systems are designed for high-throughput data analysis. Even developers might be told to bring a time series database for time series data, a search engine for full-text search, and so on.
We have noticed that most analysis and exploration tasks can be efficiently executed in a single system, by leveraging cloud-commodity object storage as primary storage, supporting flexible data modeling, and implementing adaptive indexing strategies. This approach greatly reduces data movement/duplication between different systems.
For example, real user monitoring consists of real-time queries and historical analysis. Real-time queries are based on the latest user activities for online feedback, while historical analysis involves complex aggregations over large datasets.
When the data volume is small, data engineers often choose one or several software as a service (SaaS) solutions for all of data collection, storage, and analysis. As the data volume grows, they may need to write their own agents and tools to collect events from various sources including log files. If the data volume explodes, data engineers start to build a complex data pipeline with multiple components, as shown in the first section.
For example, they often stage all the events in message brokers, fanning them out to both real-time and batch processing systems. Specifically, a stream processing job consumes events from a message broker, filtering and grouping them to produce real-time insights. This is a long-running job that continuously occupies resources to process incoming events. In contrast, the data warehouse stores all the historical data and scales out dynamically to handle large queries.
Supposed we have a simplified user actions table defined as below:
CREATE TABLE tenant.events (
ts timestamp,
message string,
source string,
application string,
var object,
)To implement full-featured real user monitoring, users first write all the events into the tenant.events table. Then, for real-time serving, users will filter table data with multiple conditions, including time range, source, and possible conditions based on fields of var:
FROM tenant.events
SELECT *, try(var["meta"]["http_url"]::string) AS `http_url`
WHERE time >= "2025-06-27T07:56:00Z"::timestamp
AND time < "2025-06-27T08:01:00Z"::timestamp
AND NOT regexp_like(`http_url`, "/path/to/data.*")
AND `source` = "nginx"
AND NOT search(`http_url`, "/path/to/directory")
GROUP BY `http_url`
AGGREGATE max(time) AS `ts`, count() AS `cnt`
ORDER BY `ts`Traditional data warehouses may struggle to execute such queries efficiently, especially when filtering based on nested fields within semi-structured data. Because they are designed to scan the entire dataset to produce reports, their indexing capabilities are too weak to avoid scanning irrelevant data blocks.
However, ScopeDB's adaptive indexing system allows users to create semantic indexes on columns or expressions:
CREATE RANGE INDEX ON tenant.events (ts);
CREATE EQUALITY INDEX ON tenant.events (ts);
CREATE EQUALITY INDEX ON tenant.events (source);
CREATE EQUALITY INDEX ON tenant.events (application);
CREATE SEARCH INDEX ON tenant.events (try(var["meta"]["http_url"]::string));
CREATE MATERIALIZED INDEX ON tenant.events (try(var["meta"]["http_url"]::string));The query above can leverage the range index on ts and the search index on http_url to efficiently filter out the irrelevant data blocks. Additionally, since a materialized index exists on http_url, the query does not need to load all the raw var data, parse it on the fly, extract the nested fields, and then pass it to the group by clause. Instead, it can directly access the pre-computed values in the materialized index.
On the other hand, batch processing over historical data can consume significant resources, as it often involves scanning large datasets and performing complex aggregations. Because existing real-time processing systems are generally designed for long-running jobs and store intermediate results in hot caches, it is too expensive to scale them out to handle batch workloads. Once scaled out, it isn't easy to scale them back in.
ScopeDB employs a serverless architecture where each compute node is stateless. Users can scale out the compute resources without limitation, and ScopeDB can leverage all the resources with its massive parallel processing capability. Once the query is finished, the resources can be released immediately without any data rebalancing burden.
What's more, ScopeDB supports table joins, allowing users to get insights from events with additional metadata. For example, users can join the tenant.events table with a tenant.apps table to analyze app releases:
CREATE TABLE tenant.apps (
name string,
version string,
release_date timestamp,
);
FROM tenant.events AS e JOIN tenant.apps AS a
ON e.application = a.name
SELECT e.*, a.name AS app_name, a.version AS app_version
WHERE e.time >= "2025-01-01T00:00:00Z"::timestamp
AND e.time < "2025-04-01T00:00:00Z"::timestamp
AND e.time >= a.release_date
AND e.time <= a.release_date + 'PT720h'::interval
GROUP BY app_name, app_version
AGGREGATE count() AS cntRecap: No More ETL
Return to the initial picture of a typical yet complex data pipeline. Rather than adding a new component to The Great ETL Landscape, ScopeDB aims to provide developer-friendly APIs in all aspects of data management:
- A unified API to collect data from different applications into ScopeDB.
- A unified query language, ScopeQL, for both ingestion reshaping and any-shape queries.
- A powerful indexing system that supports efficient real-time serving.
- A serverless architecture that allows for easy scaling for batch processing.
Here is how we place ScopeDB in the cloud data stack:

ScopeDB works for both real-time serving and batch processing workloads. Since then, ETL pipelines and storage orchestration layers can be greatly simplified or even eliminated.
If you're interested in evaluating ScopeDB, or just want to get your hands dirty, drop us an email for onboarding guidance, as well as to access the free trial endpoint.